代码地址(github)
概述
建立统一的数据存储,解决跨HBASE/HDFS/NOSQL和RDBMS数据存储系统时访问不一致,开发接口多样的问题。引入数据分层的理念, 在冷热数据处理上采取不同的策略,综合利用大数据存储和RDBMS数据存储的优势。通过Master Slave的架构设计,平台在高可用、线性扩展上继承了Hadoop生态的优点。
结构化数据可以通过RDBMS数据库,比如MYSQL,很好的处理,这么多年来MYSQL做了很好,事务处理(ACID)她能够办到,
在数据隔离性的需求不是很明朗的情况下,通常Read Committed是比较好的处理方式。
- 读未提交(Read Uncommitted)
- 读提交(Read Committed)
- 可重复读(Repeated Read)
- 串行化(Serializable)
- HDFS分布式文件存储系统解决跨多节点存储
- Hadoop生态,此前我们已经在Hadoop生态上花费了大半年的研究时间
- HBASE的高性能
随机读取能力 - HBASE的HA高可用性线扩展能力理解起来比较简单
- 可以通过HIVE无缝连接到其他的数据处理框架,比如
Impala, Hive On Spark - 通过
Phoenix插件,可以使用LIKE-SQL操作
Phoenix来操作HBASE,但是我认为Phoenix对HBASE的数据有侵入性,带来数据膨胀的问题(后面文章谈谈Phoenix的索引策略)。
架构
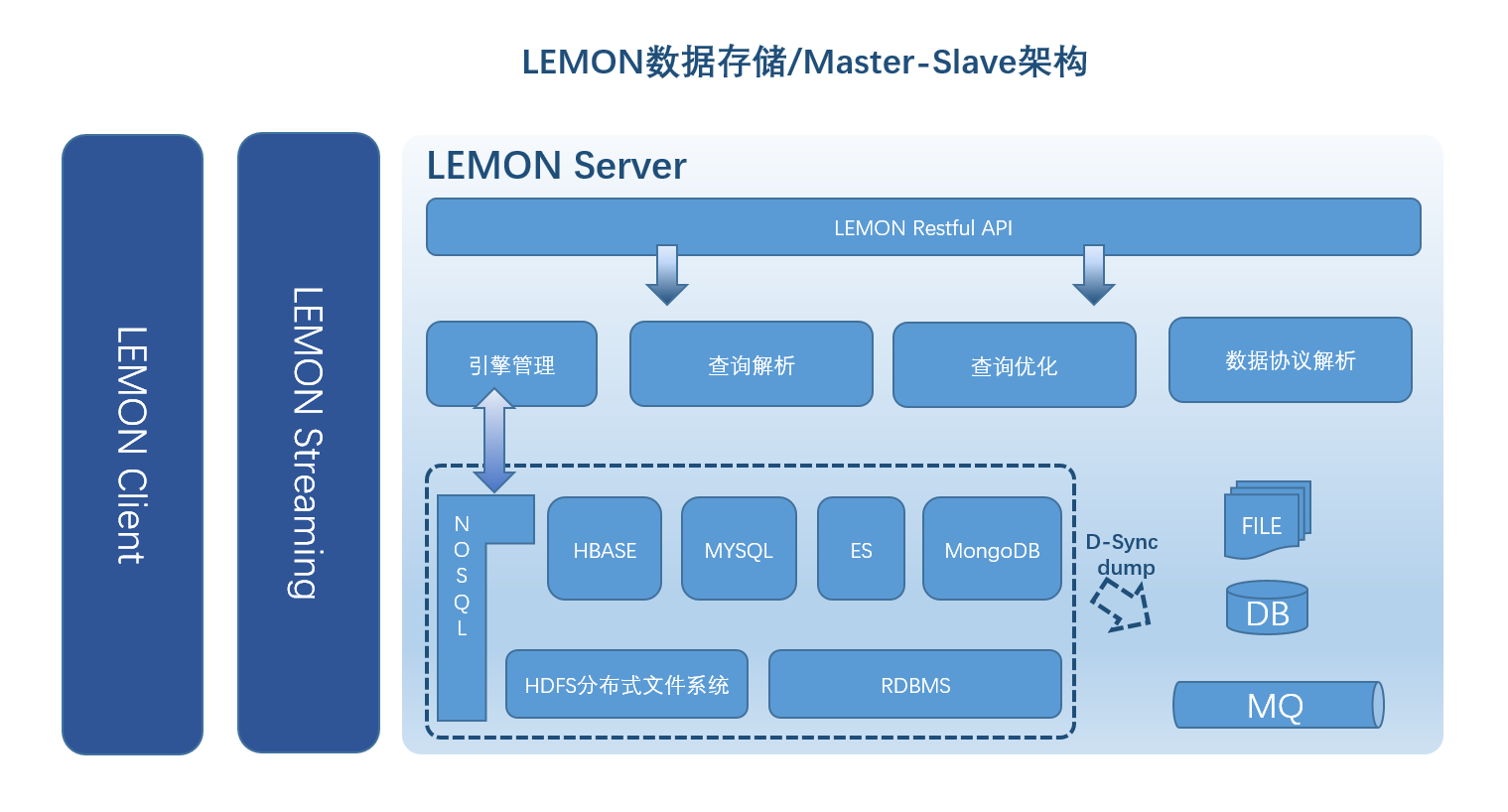
统一数据模型
由于分布式存储和RDBMS存储的数据结构差异大,查询模型不一致,往往导致复杂的接口调用;分布式存储一般基于Key-Value存储模型, 没有数据的范式定义,在主题库建设中需要元数据来表现数据。因此,通过在分布式存储的基础上提供动态伸缩的元数据定义, 提供了与RDBMS相似的范式数据定义,同时兼顾了大数据存储的高伸缩性。
定义如下 数据结构:JSON 数据类型: 1. string 字符类型 2. int 整型 3. long 长整型 4. double 浮点型 5. boolean布尔型 6. date 日期类型,值为长整型(long) 网络协议:TCP/HTTP
| 参数 | 备注 | 值 | 值备注 |
| ope | 操作类型 | insert | 插入 |
| update | 更新 | ||
| delete_row | 删除 | ||
| select | 查询 | ||
| cert | 操作凭证 | ||
| schema | 表schema | ||
| table | 表名称 | ||
| condition | 操作条件 | and | 与 |
| or | 或 | ||
| eq | 等于 | ||
| ge | 大于等于 | ||
| gt | 大于 | ||
| lt | 小于 | ||
| le | 小于等于 | ||
| lk | 相似 | ||
| limit | 查询限定返回行数 | start | limit开始 |
| end | limit结束 | ||
| result | 返回的字段和字段类型 | ||
| type | 字段数据类型 | string | 字符类型 |
| int | 整型 | ||
| long | 长整型 | ||
| double | 浮点型 | ||
| boolean | 布尔型,值为int | ||
| date | 日期类型,值为长整型(long) |
数据存储引擎
存储引擎以插件的形式在引擎中心(Engine Hub)注册,Engine Hub负责引擎生命周期的管理。引擎选择器根据不同的存储要求选择相应的存储引擎。
- 引擎中心(Engine Hub)
- HDFS存储引擎
- HBASE存储引擎
- RDBMS存储引擎
- 引擎选择器
- 插件化开发
抽象数据流
数据的进进出出抽象出数据流的概念,与此相应的我们有个数据管道的设计,数据管道设计成单向的,双向管道采用通过包装单向管道的方式。
在管道中流动的数据通过数据转换器(正向/逆向)转换成统一的数据结构/相应的数据结构(外部数据源)。根据管道不同的数据源,我们把管道分为多种形式
- RDBMS管道
- KAFKA管道
- HTTP管道
- MQ管道
- File管道
- 数据管道,单向和双向
- 数据管道的种类
- 数据转换器,包括正向转换器和逆向转换器
序列化/反序列化
使用可读性更好的JSON序列化方案,有如下几点优势和劣势
优势
- 结构良好
- 有效数据占比高,适合网络传输
- 数据结构可验证,预发现错误
- 适用面广,比如目前有的数据库也支持JSON结构了
劣势
- 序列化/反序列化耗时
- 结构不紧凑
- 元数据信息过多
Kryo XML ProtoBuff
分布式技术架构-Master Slave设计
鉴于Hadoop生态在线性扩展上良好的支持,HBASE架构在数据上的清晰处理,因此我们这个项目也采用类似HBASE的架构设计。为做到此架构下的伸缩性,保证如下几点
- Worker节点状态保证Stateless Stateless能够保证worker节点永远可以fail-fast,且对整个集群的状态不会有影响。鉴于此设计目的,我们需要保证在Worker节点上处理的任务是支持stateless的
- Master保证HA 通过Zookeeper的leader latch机制以及fast failover机制,我们能够切换到另外一个Backup的Master来支撑HA
- Backup Master保证和Master数据的同步以及状态一致的机制 数据同步我们采用如下几个机制来保证
1)同步点记录在ZK中
2)如果Master有些数据在ZK中不能记录,我们通过“有序同步记录”的方式, 在Active-Backup之间同步,通过序列号保证同步状态一致
授权、认证
这里我们摒弃中心化存储策略,比如Redis session共享,采用JWT的方式来处理请求的授权、认证问题。
模块
分布式数据同步
平台会把最近的数据同步到RDBMS数据库中,实现数据的分层。而且可以利用RDBMS数据库提供的计算能力, 比如聚合、计数、排序等,对小量的热数据做数据上的在线分析。平台通过Master分发表同步任务给相应的Worker来执行数据的同步。
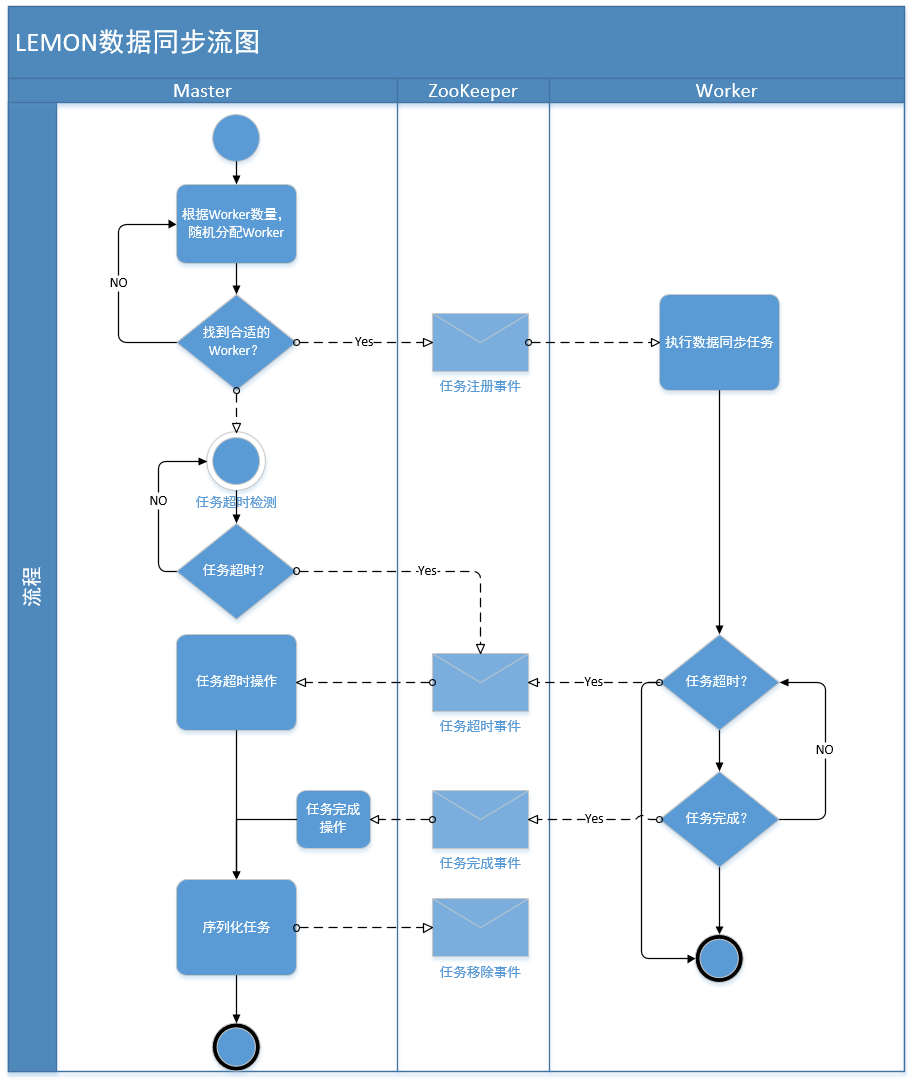
同步策略
Master同步任务产生策略
1.滚动同步策略
采取小片段的增量同步策略,能够分散数据同步的压力,避免大量数据同步时数据积压的问题,能够稳定系统的运行,时间片段可以通过配置文件配置(列出部分)
2.手动同步策略
支持用户在Lemon管理页面上自定义时间段的同步需求
Worker执行同步任务策略
1.异步策略
异步策略使用X-STREAM模块通过PUB-SUB模式异步同步数据,有着高吞吐量,但是不能保证数据同步一致性。因为同步完成通知事件是在加载完数据之后就产生了。
2.强制同步策略
强制同步策略利用SQL批插入时性能比较高的特性,在一个事务中执行全删全增操作,在同步到RDBMS数据库之后才产生同步完成事件,保证了数据同步一致性。
RDBMS数据库导入
Lemon Import Data Job,MYSQL/MSSQL/ORACLE/PG
1. 数据源{sourceMapping.source}可以从Data Source中获取;
目标表toMapping.targetTable必须在Lemon中存在Create Table;
必须配置主键:toMapping.rowKey,且主键类型会转换为string
2. 全量同步:配置 "pageSize","position","pageSql"
"taskConfig": {
"pageSql": "select * from lemon_meta_flow_task_instance order by cf_lemonRowTime limit ?,?",
"pageSize": 1000,
"position": 0
}
3.增量同步:配置 timeOffset, latestStartTime, affectFactoryParam, delayTime ,pageSql
增量同步必须有一个时间字段,且区间必须为${start},${end};
latestStartTime : 增量起始时间
timeOffset: 增量时间步长(毫秒)
delayTime: 距离系统时间System.currentTimeMillis()延迟时长(毫秒)
"taskConfig": {
"pageSql": "select * from lemon_meta_flow_task_instance where cf_lemonRowTime>=${start} and cf_lemonRowTime<${end} order by cf_lemonRowTime limit ?,?",
"latestStartTime": now(),
"timeOffset": 60000,
"delayTime": 0,
"affectFactoryParam": "{\"column\":\"cf_lemonrowtime\",\"time\":true}"
}
4.taskId为你提交任务的唯一标识,可以通过lemon_row_id=${taskId}查询你的任务状态,且也是stream hub中的topology的唯一标识5.字段值配置:
toMapping.cellMapping.sourceValue=literal|${cf_log}|function()受支持的函数:
1) concat():${code},${name},-
2) sysdate()
3) uuid()
4) sequence():1
6. 任务完成之后,Close Job
1) Close Stream in Stream Hub
2) release stream executor to pool & release all file lock...
3) Persist stream information
参考同步任务JOB JSON import-data-tempate.json
Streaming
架构
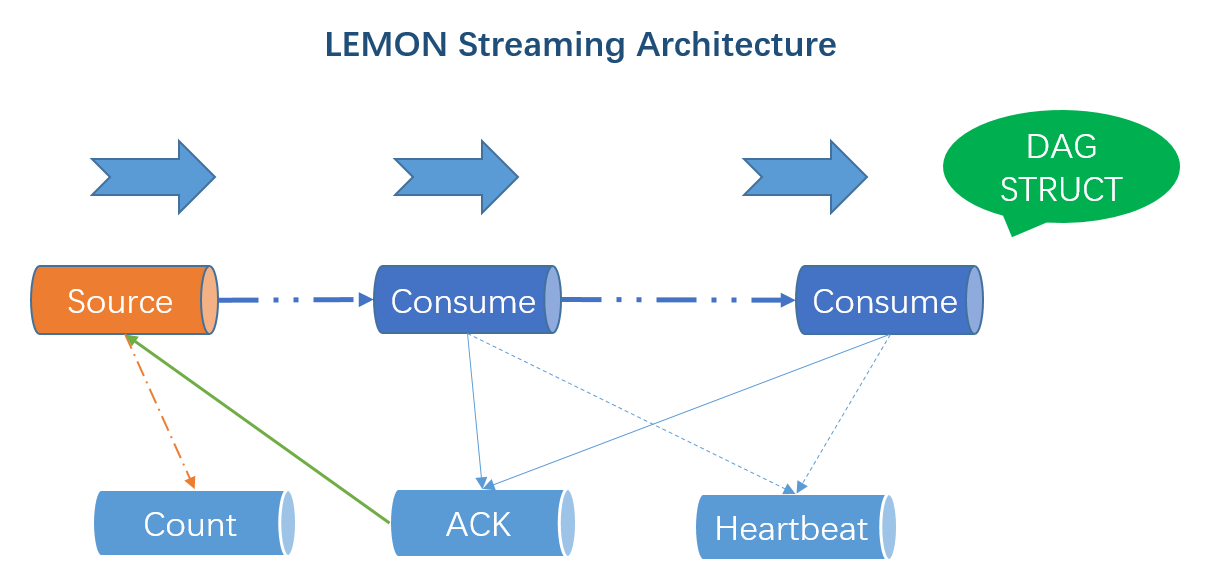
用法
参考基础框架中X-Stream模块的数据处理
客户端SDK
下载客户端SDK使用文档 客户端开发手册.docx
数据
参考“客户端开发手册.docx”
文件
参考“客户端开发手册.docx”